

Importance of data analysis in modern day organizations
Data analysis is a process related to operations on data as a result of which useful information and conclusions can be drawn. A consistent trend in recent years has been the transformation of organizations towards being data-driven. This approach has multiple benefits, some of them are:
- Better understanding of customer needs and, therefore, competitive advantage.
- Improved productivity and efficiency of development and shorter release time.
- Faster, more accurate decision-making process.
The transition to a data-driven decision-making system is not an easy task and it brings a number of challenges:
- Data processing
Data can come from multiple different sources and have different formats. It can be structured, partially structured or unstructured. The more different types of data we have to digest, the more complex workflows and pipelines can be. Additionally, when there are multiple teams working on the data, it might be challenging to provide appropriate level of access. If access to data is too strict, teams will not have up-to-date access to relevant information. The use of outdated data can lead to poor decision-making. On the other hand, unrestricted access is associated with security risks.
- Data collection reliability
The system responsible for accepting data should be reliable and scalable – as the amount of data that is generated by users can vary at different times. It is important to ensure the continuous availability of service capturing data. Perhaps data that would be lost in critical situations will be crucial from a decision-making perspective (e.g. intensified user activity at a given time).
- Ensuring data quality
The ability to store large amounts of data is one issue, but another one is to be sure that the right data is being collected. There are many methods for checking data quality. It is likely that the importance of the data will change over time. The ability to react early to changes and adapt the models is an important aspect. Dark data is information that is stored by the organization, but doesn’t have any value when it comes to decision-making. While it can account for up to 90% of stored data, it has no business value. Although it has no value, it generates storage costs.
- Keeping it up to date
Ideally, the results of the analyzed data should be provided to decision-makers so that action can be taken as soon as possible. This is a challenge especially in the age of big data where it could take a long time to process entire complete data sets from scratch. When we would have to wait days for the results of analysis, it becomes impossible to use it effectively in decision making.
- Visualization
No matter how insightful the data analysis, its value is directly proportional to the recipient’s level of understanding of the results. Raw data presented, for example, in the form of a table does not influence the recipient as much as visually appealing reports or responsive management cockpits.
AWS support for data analysis
AWS provides its users with solutions that will allow user organizations to focus on business value activities rather than technology. The growing importance of data analysis in today’s business results in a wide range of services related to storing, processing and accessing data. Data analytics was one of the important talking points at the 2022 re:Invent conference.
Serverless Analytics Services by AWS
Athena – Interactive Queries
Amazon Athena is a solution designed to perform highly scalable analytics on data. It is integrated with S3 and Glue to gather analysis data from different sources.
One of the recent additions is integration with Apache Spark. Athena notebooks can be configured to work with the underlying optimized Apache Spark engine. Service sets up all required configurations for the user to run the notebook within Spark clusters. Notebook calculation information is stored in the S3 and users can conveniently access information regarding particular calculation executions.
EMR – Big Data Processing
As mentioned previously – some of the challenges in data analytics are data size and data diversity. There are platforms addressing these issues, one of most popular are:
- Hadoop – platform for distributed processing of large data sets across clusters of computers;
- Spark – engine for executing computing data operations on single-node machines or clusters.
While helpful, users might find these solutions difficult to work with and costly. Additionally, there’s a security aspect – we need to ensure that only authorized entities will have access to the data lake. EMR is meant to provide easy use of Spark and Hadoop. It decouples compute and store, which results in better resource optimization. This service relieves users of the need for setup and configuration of the underlying system, provides automatic resizing of clusters and so on.
EMR Studio is an IDE created to elevate development, visualization, and debugging of data-focused applications. It comes up with managed notebooks with easy collaboration using code repositories (it can connect to AWS CodeCommit, GitHub and Bitbucket). Workspaces can be attached to existing EMR clusters or create new ones, using preconfigured catalog templates.
Kinesis – Real Time Analytics
Kinesis is a service that makes it easier to process streaming data at a scale. It is streaming data in real-time, therefore users can analyze and respond to data instantly. Besides standard Data Streams service, Kinesis brings forth other types of streaming data services:
- Video streaming – optimized to store and process video data;
- Data Firehose – loading data streams into data storage (lakes, warehouses, analytics services);
- Data Analytics – utilizes Apache Flink to provide insights on streaming data.
Redshift – Data Warehousing
Redshift is a cloud data warehousing service. It utilizes SQL language to analyze large amounts of data quickly and cost-effectively. It’s easily integrated with other AWS services like S3 and Kinesis.
Glue – Data Integration
AWS Glue is an ETL service. ETLs are one of the most complex aspects of data manipulation. Often a lot of code is required to perform transformations. Glue is designed to simplify this process. It allows processing data from a variety of sources, such as S3, Redshift, etc. Additionally, Glue introduces workflows that orchestrate and visualize complex ETL activities. Another feature provided by Glue are crawlers that are used to classify raw data and group it into tables and partitions.
QuickSight – BI Tool
QuickSight is a cloud service that provides easy to understand insights on data. Similarly to other services, it combines data from multiple sources. It allows creating visually appealing interactive and security accessible dashboards and paginated reports. Moreover, QuickSight Q uses machine learning to answer questions provided in natural language.
How easy is it to start working with serverless data analytics?
Below there are examples of setting up infrastructure for two AWS services – Athena Notebook and EMR Studio. Both of them use underlying advanced technology that would require a lot of configuration in on-premise setup. It’d get more complicated to maintain as the scale increases. Using serverless solutions allows us to start working on data analysis within minutes.
Quickstart with Amazon Athena
- Go to Amazon Athena service.
- Under the ‘Get started’ section select ‘Analyze your data’ and press ‘Create workgroup’.
- Fill the ‘Workgroup name’ field.
- Select ‘Apache Spark’ under the Analytics engine and check ‘Turn on example notebook’.
- Select use defaults in Additional Configuration or use custom one, if necessary, and press ‘Create workgroup’.
- You will be redirected to the Athena Workgroups, after selecting the created workgroup you’ll see its details and existing notebooks.
- After selecting an example notebook, it will be opened:
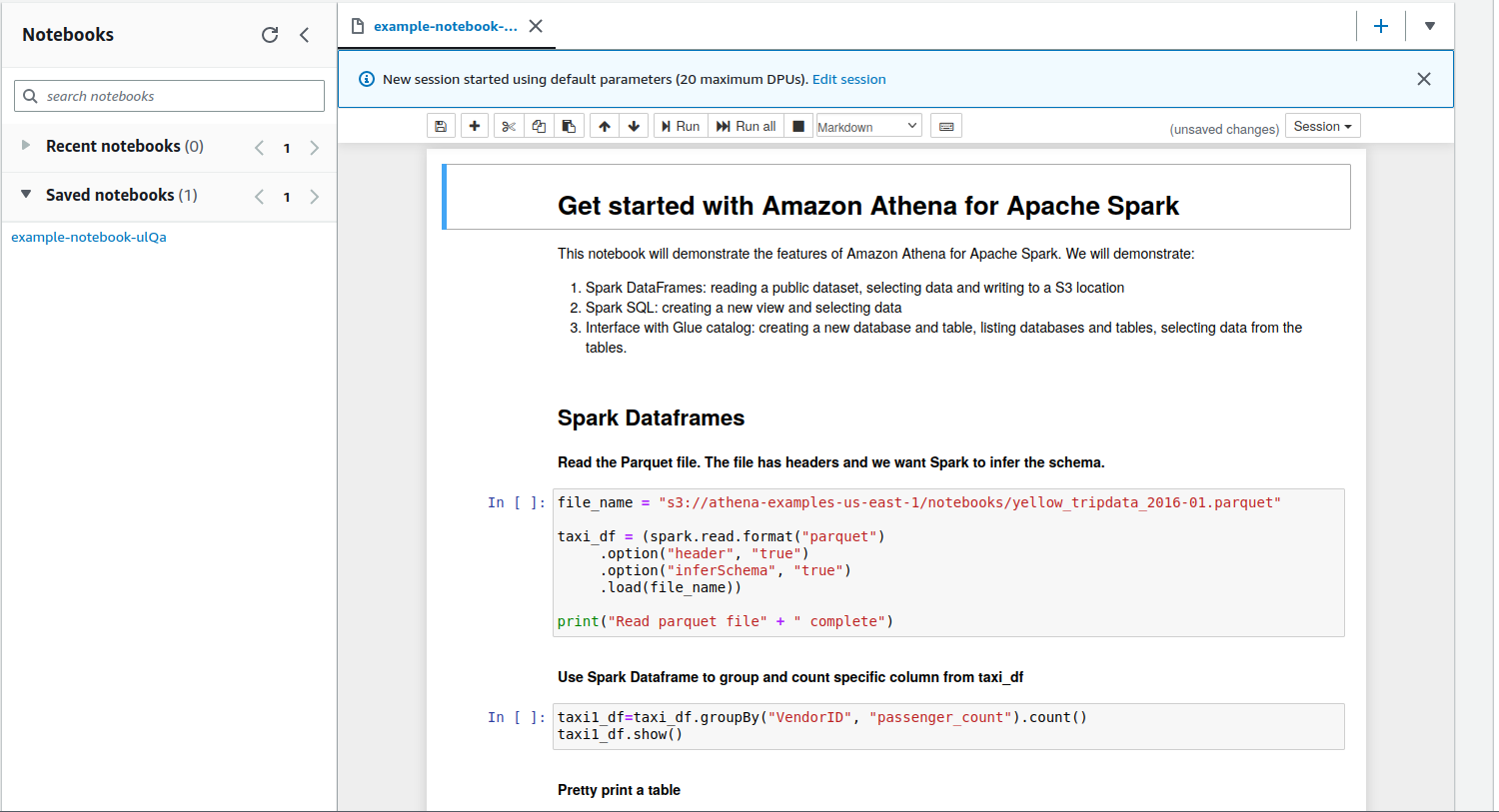
You can press ‘Run all’ to calculate all notebook operations. After it’s done, the Notebook’s state will be saved.
Within a few clicks we’ve managed to create a fully functioning computing notebook with underlying Spark Engine that can be easily integrated with S3 and Glue.
When it comes to pricing, Athena Spark costs $0.35 per DPU-hour billed per second. Single notebook can run on up to 20 DPUs at the time. Cost can be optimized by better data management, that is compressing, partitioning and converting to the columnar format.
Quickstart with EMR
- Go to EMR service.
- Select EMR Serverless.
- Press `Get Started` and create a new EMR Studio.
- Fill in the name in Application settings, set type to Spark and Architecture to x86_64.
- Choose default settings and confirm by pressing ‘Create application’.
- From the Applications view select your application.
- In Job runs card press ‘Submit job’ .
- Select relevant IAM role and path to Python script that utilizes PySpark to perform calculations.
- After the Job is submitted, it’ll be automatically executed. When execution is done, the Job is marked as Success.
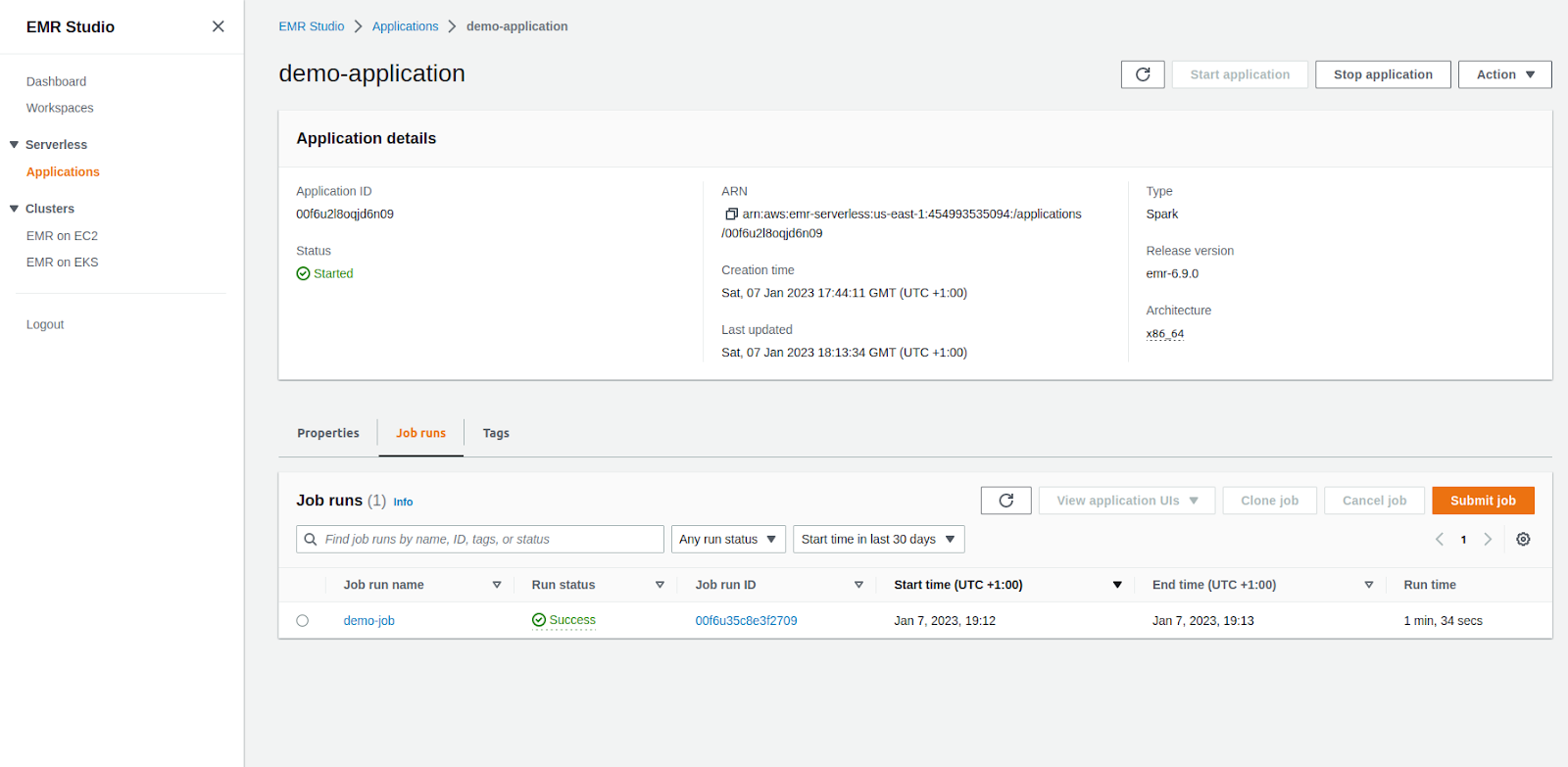
When it comes to pricing, EMR serverless billing is based only on the resources we use. It costs $0.01 per vCPU unit per hour and $0.0011 per GB per hour. There are no additional upfront costs.
Summary
As presented, solutions provided by AWS meet the expectations of data scientists by providing solutions that address many of the challenges associated with modern day data analytics. Services like EMR, and Athena enable analyzing data on a huge scale and remove the need for the user to take care of the infrastructure. S3 and Redshift are reliable data storage tools and QuickSight is a tool designed for building dashboards that are easy to use and analyze, and for creating reports from different data sources. All of the services mentioned above are serverless and cost effective – we pay only for resources we consume during data processing.
Find out more about AWS tools: AWS Solutions for Event-Driven Architecture.











